We propose using action reconstruction as a scoring criterion for synthesized reasoning traces in user modeling, yielding more causally faithful reasoning and improved downstream action prediction.
Abstract
User modeling aims to use language models (LMs) to mimic an individual’s behavior from a corpus of past context–action pairs (e.g., conversation turns), enabling the simulation of users in settings like behavioral science, human–AI collaboration, and market research. Recent approaches augment these corpora with synthesized reasoning traces, typically generated by conditioning on both context and action. However, such conditioning constitutes post-hoc rationalization rather than reasoning: the trace is guaranteed to justify the action, but may not encode the underlying latent causal decision paths. We propose RECON, which uses action reconstruction to score reasoning traces by their predictive power: given a context and candidate reasoning, a reconstruction model predicts the action, and reconstruction fidelity determines reasoning quality. Across four domains, RECON achieves a 54.7% win rate over the post-hoc rationalization baseline. Further, training a reasoning synthesis model with rewards derived from RECON improves downstream performance, achieving win rates of up to 70.0% over baselines. We further show that RECON-synthesized reasoning transfers across models and improves user modeling beyond the reconstruction model itself.
Evaluation Domains
We evaluate across four free-form conversation domains spanning formal legal proceedings to casual online debate, modeling eight individuals in total. In each domain, context is a sequence of prior conversation turns and the action is an individual’s next-turn response.
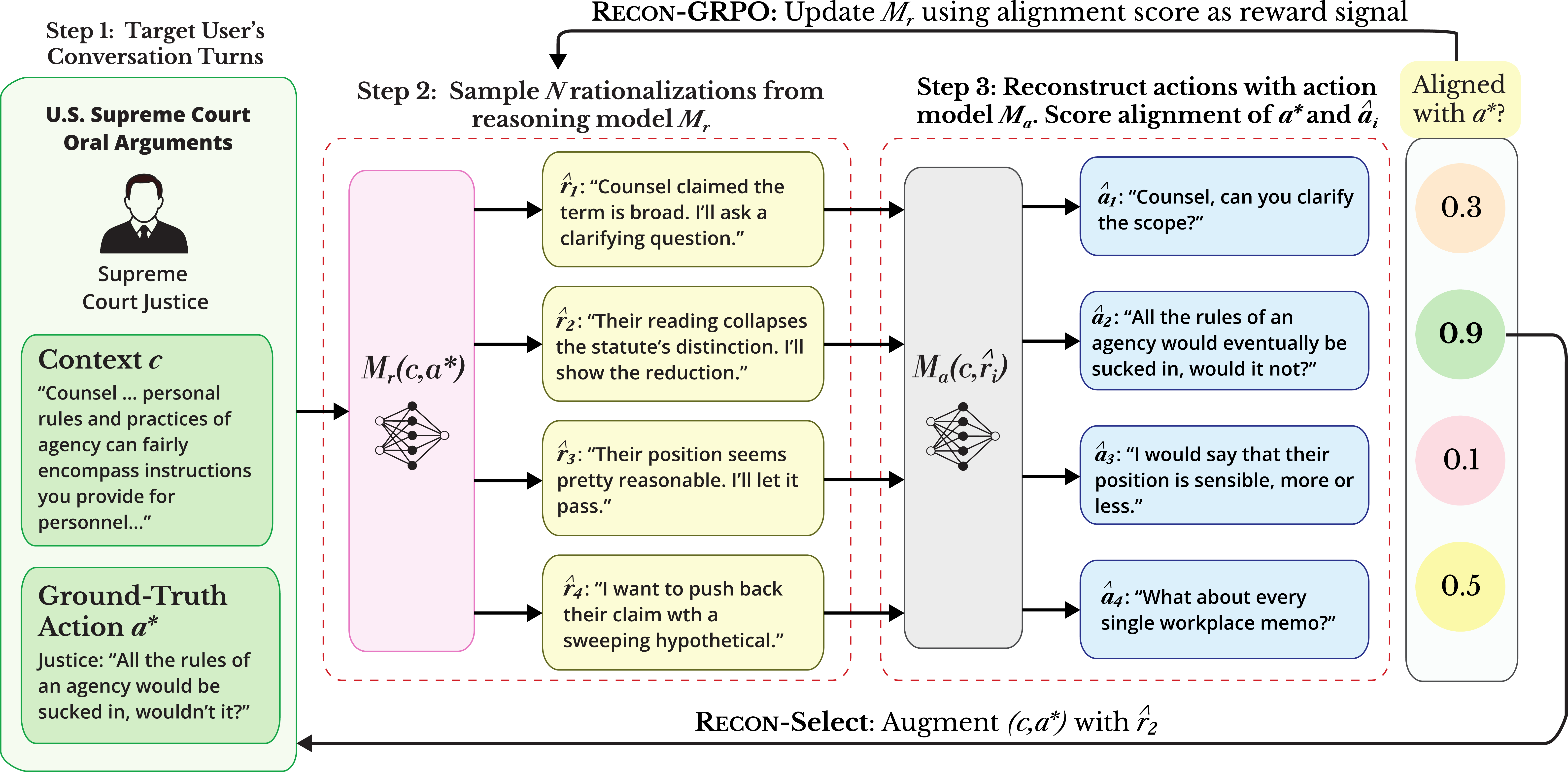
Standard reasoning synthesis conditions on both context and the ground-truth action, producing rationalizations that are consistent with the action but need not explain why the user chose it over alternatives. RECON addresses this by scoring candidate rationalizations through action reconstruction: given the original context and a synthesized reasoning trace, can a model recover the user’s observed action? High reconstruction fidelity is a tractable proxy for causal, latent reasoning.
RECON-Select
Training-free. Sample N=4 candidate rationalizations, reconstruct the action from each, and select the trace whose reconstruction best matches the observed action.
RECON-GRPO
RL-based training. Use reconstruction alignment as a GRPO reward to fine-tune the reasoning synthesizer. The frozen action model forces interpretable, model-agnostic traces.
The RECON pipeline. Given a context–action pair, N=4 candidate rationalizations are sampled from a reasoning model conditioned on context and action. Each is scored by prompting an action model with only the context and reasoning to reconstruct the action; alignment with the ground truth action determines reasoning quality. RECON-Select picks the best trace; RECON-GRPO uses the scores as a training reward.
Results
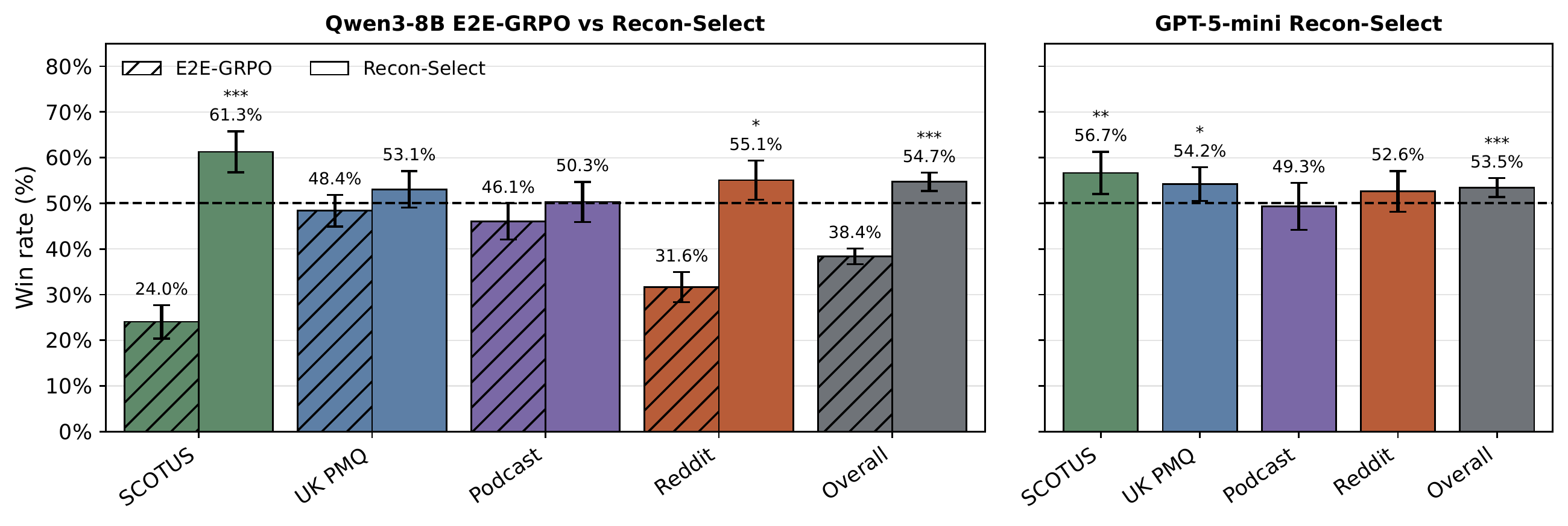
We evaluate by measuring win rate against Backward Synthesis — the simple post-hoc rationalization — in a retrieval-augmented generation pipeline. An LM judge compares generated actions to ground truth along three dimensions (style, intent, values).
We compare three methods: RECON-Select (best-of-N selection), RECON-GRPO (reasoning synthesizer trained with reconstruction rewards), and E2E-GRPO, a trained baseline that generates both reasoning and action end-to-end, rewarded solely on whether the generated action matches the ground truth. E2E-GRPO represents the natural RL alternative: rather than scoring reasoning by reconstruction fidelity, it optimizes reasoning implicitly by rewarding action accuracy.
54.7%
RECON-Select win rate (Qwen3-8B)
70.0%
RECON-GRPO win rate (Qwen3-4B on PMQ)
38.4%
E2E-GRPO win rate (Qwen3-8B)
All win rates vs. Backward Synthesis baseline (ties excluded).
Win rates against Backward Synthesis. Left: Qwen3-8B results including RECON-Select and the trained variants. Right: GPT-5-mini results. RECON-Select consistently exceeds 50% across all domains; notably, E2E-GRPO (training to maximize action accuracy alone) significantly degrades performance.
Qualitative Example
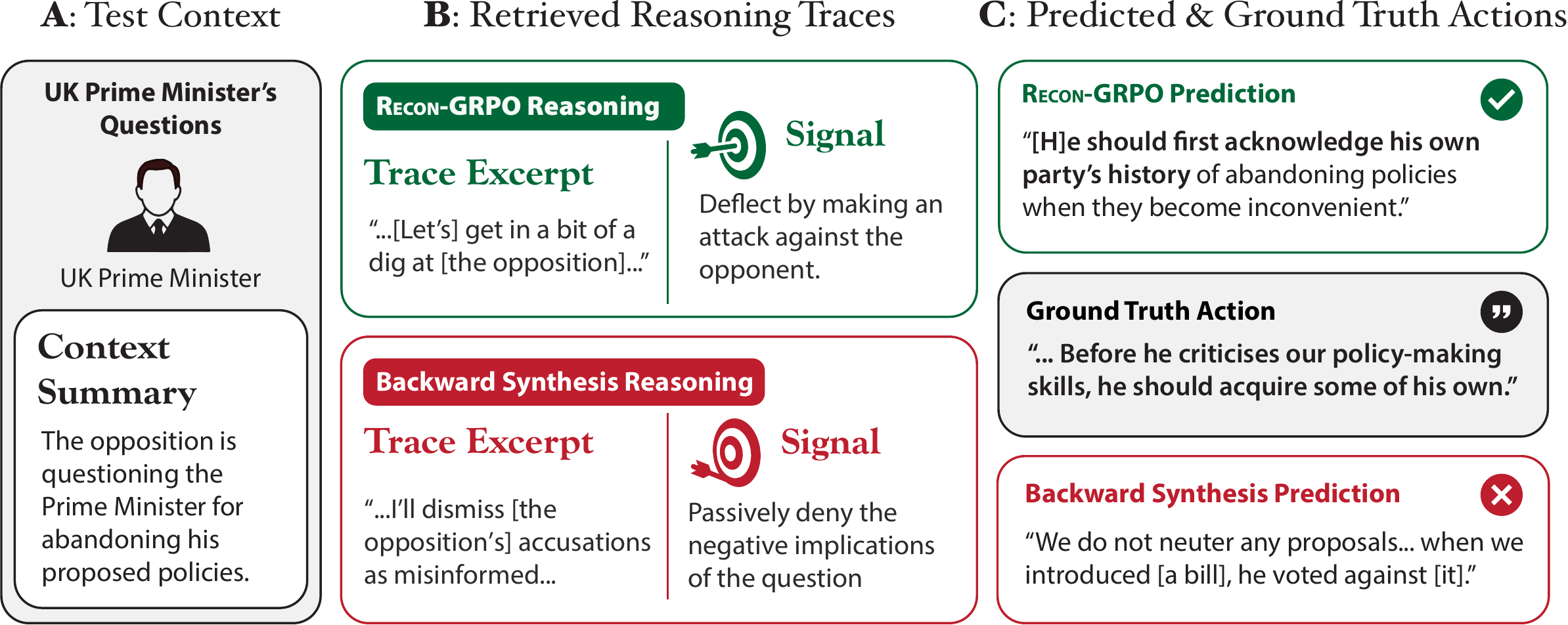
In the PMQ domain, RECON-GRPO learns to identify the Prime Minister’s rhetorical strategy — attacking the opposition rather than responding defensively — and produces reasoning that guides the action model toward a response much closer to the ground truth. The post-hoc rationalization baseline, by contrast, produces a defensive framing that misses the PM’s communicative intent.
Qualitative comparison (PMQ domain). RECON-GRPO identifies the PM’s intended rhetorical move (attack) and generates reasoning that guides the action model toward the ground-truth response. Backward Synthesis produces a consistent-but-wrong rationalization that leads the model astray.
Citation
@misc{zhu2026recon,
title={Recon: Reconstruction-Guided Reasoning Synthesis for User Modeling},
author={Alan Zhu and Mihran Miroyan and Carolyn Wang and Andrew Zhou and Lisa Dunlap and Narges Norouzi and Joseph E. Gonzalez},
year={2026},
eprint={2605.26969},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2605.26969},
}